Engineering managers
Need startup risk surfaced early enough to stop firefighting from consuming sprint capacity.
NeuralShell helps engineering, platform, and reliability teams see degraded startup paths earlier, isolate unstable runtime surfaces, export structured trace evidence, and move toward cleaner release decisions.
This is for teams dealing with long triage loops, weak operational evidence, and startup failure that blocks work before value starts.
NeuralShell is positioned for platform-heavy teams where runtime instability and weak incident evidence slow down decisions.
Need startup risk surfaced early enough to stop firefighting from consuming sprint capacity.
Need repeatable controls for runtime health, controlled isolation, and traceable evidence exports.
Need cleaner go or hold decisions when startup paths degrade before value starts.
Need deterministic operator loops under changing plugin/runtime surfaces, not another generic AI assistant.
Initial instability holds back meaningful validation before teams can observe real workload behavior.
Runtime and plugin surfaces diverge across environments, causing inconsistent outcomes and repeated regressions.
Teams spend too much time reconstructing startup state and too little time correcting the root failure path.
Without structured evidence, release calls become subjective and high-friction across engineering stakeholders.
NeuralShell is not another generic AI tool. It is a control layer for unstable startup paths and proof-backed release decisions.
Establish explicit startup checks before downstream work begins so degraded paths are visible immediately.
Isolate unstable runtime surfaces to reduce blast radius and speed targeted remediation.
Export structured trace evidence for incident review, auditability, and faster engineering handoffs.
Gate release confidence using observable evidence rather than assumptions or generic AI-output confidence.
The reliability story must stay concrete: startup issue detected, visibility improves, unstable surface isolated, trace exported, and release confidence restored.
Teams can quickly identify degraded startup behavior before dependent workflows begin to fail silently.
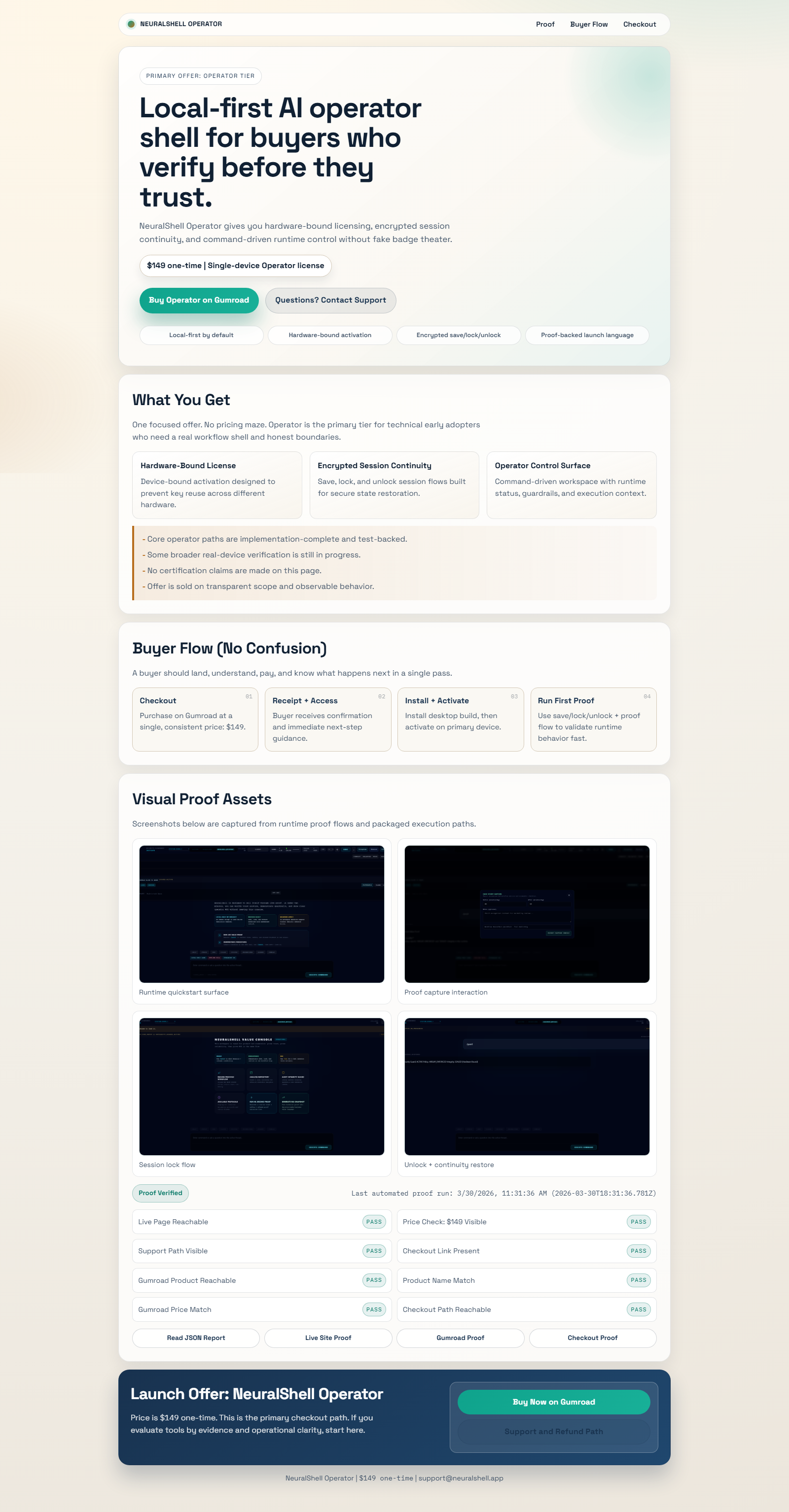
Control checks and report state provide a readable startup health snapshot for platform and reliability owners.
Plugin/runtime drift is isolated so teams can reduce blast radius and recover deterministic startup behavior.
Structured evidence is exported for reproducible incident review and cross-team debugging continuity.
Release calls are made from observable startup and runtime evidence instead of vague confidence language.
Faster first-pass understanding of startup failures and fewer dead-end debugging loops.
Teams isolate unstable surfaces sooner and regain control faster during reliability incidents.
Trace exports and structured checks make cross-functional postmortems more repeatable and less subjective.
Engineering and release stakeholders can align on evidence-backed confidence gates.
The pilot is scoped for buyer clarity and operational proof, not vague discovery consulting.
If startup failures and long triage loops are slowing release confidence, use the walkthrough and proof flow to evaluate fit quickly.